What sorts of systems can be deceptive?
The following is a crosspost from the alignment forum. This work was done as part of SERI MATS, under Leo Gao’s guidance. Thank you to Erik Jenner and Johannes Treutlein for discussions and comments on the draft.
I’m interested in understanding deception in machine intelligence better. Specifically, I want to understand what precursors there are to deceptive alignment, and whether upon observing these precursors, we can change our approach to achieve better outcomes. In this article, I outline my current thinking on this topic, and consider a bunch of properties that systems which can be deceptive might share. I am still pretty confused about how this works, and I don’t yet have good ideas for what comes next.
Preliminaries
What is deception?
Commonly, by deception we mean a scenario where an intelligent system behaves in a way that hides what information it knows from another system, or from a human overseer. Fundamentally, the reason to be deceptive is that behaving honestly would lead to the system being penalised by its designers, perhaps through a training process that can intervene directly on its internal mechanisms.
In the context of Risks from Learned Optimization, deceptive alignment occurs when a system internally has a goal other than what we would like it to be. If this system is aware that it might be shut down or altered if it revealed this discrepancy, it is incentivised to play along, i.e. behave as though it is optimising the humans’ goal. Once the training process is complete and the system is safe to pursue its own goal, it does so without repercussions.
As described in the paper, deception is an inner misalignment failure, i.e. in the system there exists an inner optimiser whose goals may be different to the base optimiser’s goals. If this is the case, even if we select for models which appear to seek our base objective, the objective they actually end up pursuing may be different. These systems are deceptively aligned.
In this framing, the main way we might get deceptive alignment is through a system that performs internal search. While search is a central example, I’m curious to understand more generally what the prerequisites are for deceptive alignment. I’m particularly interested in the connection with consequentialism. In a sense, deception is just one of the many strategies a consequentialist agent might use to achieve its goals.
How does the idea of optimisation matter here?
In this article, I use “optimisation” in the context of an optimising system – a system which tends to reconfigure a space toward a small set of target states, while being robust to perturbation. This does not require the existence of a part of the system which is doing the optimisation, i.e. a separate optimiser. In this view, I think it’s possible to have a continuum of optimising systems, ranging from search over possible actions on one extreme to a set of heuristics on the other, such that all these systems outwardly behave as consequentialists, regardless of how they’re implemented.
This is related to the view that some folks at MIRI have that consequentialism is about the work that’s being done, rather than the type of system that is carrying it out. If that is the case, then in the limit of generalisation capability (i.e. systems which exhibit robust generalisation), it doesn’t matter how the system is implemented – specifically, whether it’s doing search or not – for how likely it is to exhibit deceptive behaviour. Note that my impression of Eliezer’s view on this is that he does think that you can build a weaker system which doesn’t exhibit some undesirable property such as deception, but that this weaker system is just not enough to carry out a pivotal act. (I base this mostly on Eliezer’s and Richard’s conversation.)
What properties are upstream of deception?
Let’s assume that some system has a consequentialist objective. This system lies somewhere on an axis of generalisation capability. On one extreme of this axis are controllers, systems which can be arbitrarily capable at carrying out their intended purpose, but which cannot extrapolate to other tasks. By “arbitrarily capable” I mean to hint that controllers can be very complex, i.e. they may have to carry out quite difficult tasks, by our standards, while still not being able to generalise to other tasks. One exception might be if those tasks are subtasks of their initial task, in the same way “boil water” is a subtask of a robot that makes coffee.
In my model, controllers don’t “want” anything, not even with respect to accomplishing the task they have. Thermostats don’t want to regulate temperature; they just have a set of rules and heuristics that apply in particular scenarios. If the thermostat has a rule: “if the temperature is under 20C, turn on the heating”, there’s no sense in which it “wants” to turn on the heating when the room is cold; it just does so. If this rule were removed and there were no other rules looking at the same scenario, the thermostat wouldn’t try to find a way around the removal and still turn the heating on; it would not even know it needed to. It seems unlikely that controllers would be deceptively aligned.
On the other extreme of the axis are optimisers. These are systems which can generalise to states that were not encountered during the training process. In particular, they can generalise an objective of the type “do whatever it takes to achieve X” from states seen during training to states encountered during deployment. These systems can be deceptively aligned.
We kind of understand what systems look like in these extremes, but it’s unclear to me what characteristics intermediate systems – those which are some mix of searching and heuristic behaviour – have. It seems important to find this out, given that neural networks seem to be somewhere on this continuum. If scaling deep learning leads to systems which generalise better – and thus are more like optimisers – then we’ll hit a point where deceptive alignment is “natural”.
Disentangling generalisation and consequentialism
Here’s an idea: to have systems which are deceptively aligned, you need them to both have a consequentialist objective and have high generalisation capability.
I’ll continue with the same axis I described in the previous section. On one end are low-generalisation systems like look-up tables, expert systems and bags of heuristics. On the other, are searchy, optimiser-like systems, which generalise well to unseen states. Another way to think about this is: on one extreme, the outer training loop does the heavy lifting. All strategies are learned during the training process, and there is no mechanism by which a system can learn after deployment. On the other, the inner loop does most of the work; it finds new strategies at runtime, probably using search. Things in the middle use a combination of memorisation of data, rules, heuristics learned during training, as well as some degree of in-context/online learning. GPT seems to be somewhere between lookup tables and AIXI, probably closer to the former.
To see how deception arises in my model, I want to introduce a new axis. On this axis, systems range from “has a non-consequentialist objective” to “has a consequentialist objective”. Here, the objective is the objective of the system. In the case of a controller, it’s a behavioural objective, in the sense that we could accurately model the controller’s behaviour as “trying to achieve X”. For optimisers, the objective refers to their mesa-objective. This coordinate system also implies a “base objective” axis – this is not the same as the y-axis in the figure.
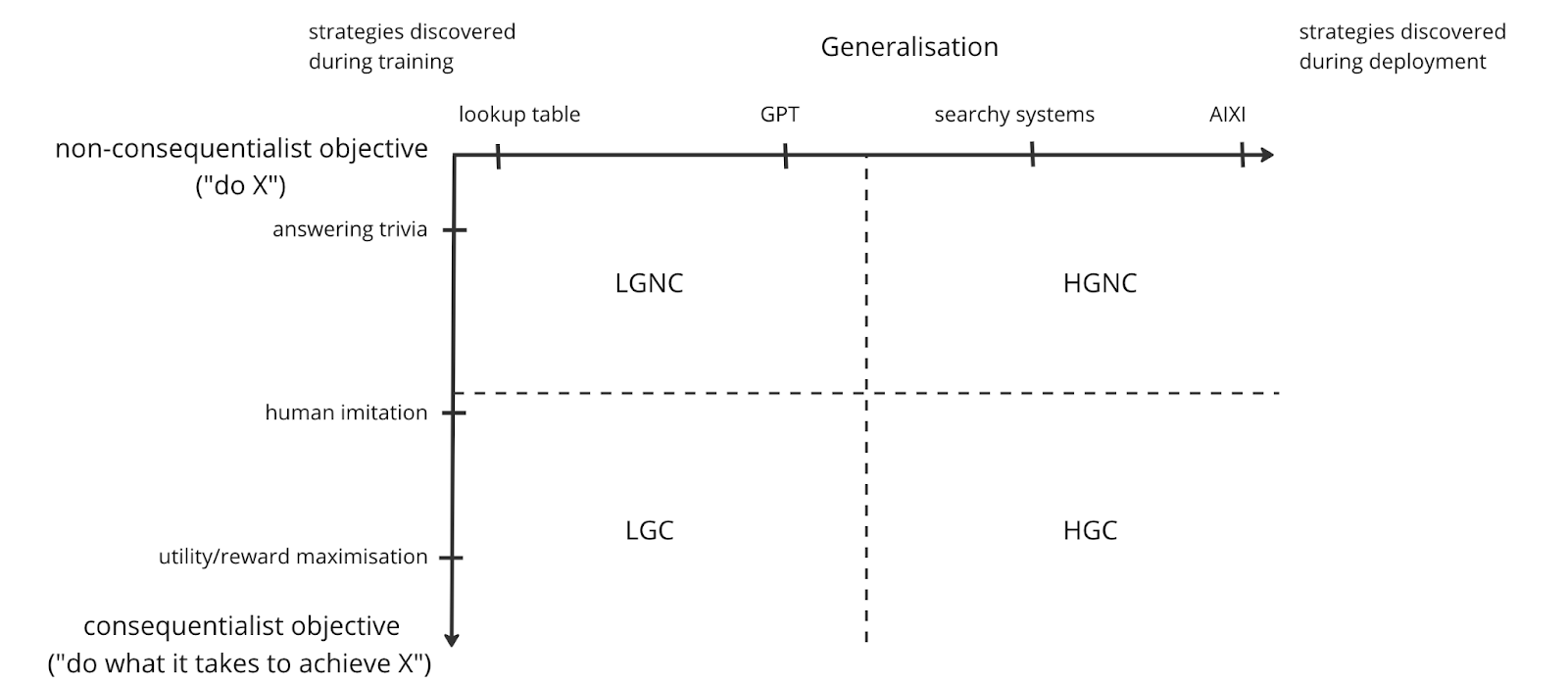
A 2D system of coordinates: generalisation capability against consequentialism in the behavioural objective.
I want to examine four cases, corresponding to four imaginary quadrants (I don’t think there will be a meaningful boundary, nor do I think that the quadrants are drawn realistically, i.e. that GPT is LGNC. I’m using this for the sake of analysis):
- Low-generalisation, non-consequentialist objective (LGNC) systems: designed to achieve a task that is relatively simple, and which cannot extrapolate past that task. For example, a trivia system that memorises and retrieves facts about the world, without modelling agents.
- Low-generalisation, consequentialist objective (LGC) systems: designed to achieve a complex task that requires completing lots of smaller steps, and potentially figuring out what those steps are. An example here is a tabular policy learned using RL.
- High-generalisation, non-consequentialist objective (HGNC) systems: searchy things which accomplish some relatively simple task, like retrieving a fact about the world without modelling agents.
- High-generalisation, consequentialist objective (HGC) systems: searchy things with complex goals which require planning and achieving other subtasks, not being turned off or modified, the usual.
I’m going to make a bunch of claims regarding these four quadrants/regimes, all of which are intuitions rather than hypotheses which I currently have lots of evidence for. Here goes:
- LGNC systems cannot be deceptive except through Goodharting on the task, as discussed here. This is because these systems can’t generalise beyond what they were trained on, and cannot discover deceptive strategies at runtime, through search. For these systems, their capability comes largely from the training process. LGNC systems are safe but useless.
- Similarly, LGC can only carry out deception if they observed it in the training data. Because they have low generalisation capability, they can’t extrapolate or recompose it from examples which did not show deception.
- HGNC systems can be deceptive, but they are somewhat less dangerous than their consequentialist counterparts. These approximately map onto tool AIs. It seems like these aren’t a central problem, as there are economic incentives for HGC systems to develop rather than HGNC systems.
- Deception does arise when moving from HGNC to HGC systems (acquiring consequentialism – “motive”) or from LGC to HGC systems (acquiring generalisation power/search capabilities – “means”). These systems are very likely to be deceptive, if deception turns out to be a useful strategy for achieving their goals. These systems behave coherently and can be described as maximising some utility function.
Insofar as these two axes are separate, I imagine that there’s something like a Pareto front in the space of possible models, such that we can get most of our capability for the least amount of risk of deception possible. This is the way in which I see further work in this area to be impactful.
Where this falls short
There are various things here that confuse me, the main being what the x-axis represents. There is something unsatisfying about saying that deception happens because of generalisation capability and calling it a day. I’m interested if we can pinpoint deception even more precisely, in terms of properties like Ajeya’s situational awareness (“playing the training game”), or goal-directedness. In other words, what mechanisms enable deceptive alignment, and where do they emerge as a system becomes more capable?
Another confusion regarding this 2D system idea is that the two axes are not orthogonal. In my view, it’s not possible to become more capable and not become consequentialist at all. This is because systems become more capable as they are trained on scenarios that are more varied, more broad, and more complex. That gets you consequentialism. Still, even if the axes are correlated, it doesn’t mean that all systems lie on the first diagonal, and for every increase in capability you get a proportional increase in consequentialism.
Appendix: Degree of coupling?
It seems like an axis which overlaps to a significant degree with generalisation ability is the degree of internal coupling of the system. On the low-coupling extreme, each of a system’s components is practically independent from the others. Their effects can chain together, such that after component A fulfils its purpose, component B can activate if its conditions are met. But there are no situations where in order for the system to achieve some behaviour two components need to fire at the same time, or be in two particular states, or interact in a specific way.
Moving toward the right on this axis, we get systems which are more coupled. There are behaviours which require more complex interactions between components, and these incentivise a sort of internal restructuring. For example, it’s likely that components are reused to produce distinct behaviours: A + X = B1, A + Y = B2. I think it’s the case that some components become very general, and so are used more often. Others remain specialised, and are only seldom used.
In my model, the further along this axis a system is, the more it relies on general components rather than case-specific heuristics and rules. A fully coupled system is one which uses only a handful of components which always interact in complex ways. In an extreme case, a system may use just one component – for example an exhaustive search over world states which maximise a utility function.
If coupling is something we observe in more capable systems, it might have implications for e.g. how useful our interpretability techniques are for detecting particular types of cognition.