Why you might expect homogeneous takeoff: evidence from ML research
The below is a cross-post from the alignment forum.
Introduction
This article aims to draw a connection between recent ML research and the claim that future advanced AI systems may be homogenous. First, I briefly review this article, where the idea of homogenous take-off is introduced. Then, I outline two different arguments why you might update in the direction of homogenous take-off. For each of the arguments I mention key uncertainties that I have about the argument itself, as well as broader open questions.
TL; DR
I present two reasons to believe that as models become larger they also become more homogenous, i.e. they behave more similarly to each other:
- Variance between models behaves unimodally in the overparameterised regime: it peaks around the interpolation threshold, then decreases monotonically. Decreased variance means that models make similar predictions across different training runs (captured as variance from initialisation) and different sampling of the training data (variance from sampling);
- Neural networks have a strong simplicity bias even before training, which might mean that multiple training runs with different hyperparameters, initialisation schemes etc. result in essentially the same model.
I’ve somewhat updated in the direction of homogenous take-off as a result of these arguments, though I think that there are still ways in which it’s unclear if e.g. decreasing variance with size rules out heterogeneity.
What’s homogeneous take-off?
There are several axes along which different AI takeoff scenarios could differ: speed, continuity, and number of main actors. Homogeneity vs. heterogeneity in AI takeoff scenarios introduces a new way to look at a potential take-off, through the lens of model homogeneity. Homogeneity intuitively refers to how similar models are at any given time given some definition of similarity. We might specifically refer to homogeneity with regards to alignment, which, again intuitively, means “models are more or less aligned to the same degree” (or: “aligned models will not coexist with unaligned models”).
More formally we mean something like models having similar properties, e.g. alignment properties. In my mind, an alignment property might be something like “corrigibility” or “truthfulness”, though it’s unclear to me to what extent two models which are, say, truthful, are also homogenous. I think working toward a clearer, more precise definition of homogeneity is probably useful in determining what actually counts as evidence for homogenous systems being more likely, though I don’t try to do so in this write-up.
The article sets out a list of arguments supporting the idea of homogenous take-off, which I parse as “evidence from the economics of large scale machine learning”. Without going into too much detail – I recommend reading the original article for the full arguments –, these are:
- Training a model is more expensive than running it. This is a relatively straightforward claim which extrapolates from the landscape we have today, where some large language models reportedly have had training budgets in the millions of US dollars, with comparatively little cost to run inference/serve the models themselves once trained.
- Training models from scratch is not competitive once the first advanced system is released. To me this follows from 1., in the sense that if it is economically useful to deploy more than one model simultaneously, it’s likely that the additional models will be copies of the original (perhaps fine-tuned on different tasks) rather than new models trained from scratch.
- Copying is more competitive than (untested) alternative approaches. Here I think it’s worth disentangling two ways of copying:
- Direct copying of the first advanced system, possibly by using the same weights, or by running the exact same training process. There are reasons to believe that direct copying might not be possible or even desirable, since e.g. states might not want to use a competing state’s advanced system.
- Indirect copying is using the same techniques as the creators of the original system, but not identical training runs/hyperparameters. This scenario seems more likely to me, and it’s here where the arguments I present on variance/simplicity bias are most important, since they show that different runs may not necessarily result in different models.
- Homogeneity is preserved during initial takeoff. Here the argument is that later generations of AIs will also be homogenous, at least with respect to alignment. This is because we either use the first generation systems to align the next generations, or we use ~the same techniques we used on the 1st generation to align the next generations. The idea is that both approaches result in systems with the same alignment properties. It’s unclear to me whether the same kind of argument holds for something other than alignment properties – and if not, why not.
In this article I want to present two technical arguments from recent ML research that support the idea of homogenous take-off. First, as models become larger, variance between models decreases. Second, neural networks seem to be biased toward simple solutions even before training.
Argument from variance
Bias-variance decomposition
One of the main practical insights of statistical learning theory is related to the bias-variance decomposition of mean squared error. In this section I’ll be introducing the concepts of bias and variance and discussing their importance in the classical and the overparameterised regimes. I’ll be using the notation from Adlam & Pennington, 2020.
The main idea is that for a supervised learning task where a model (\(\hat{y}\)) is minimising mean squared error on a training set \(\mathcal{D}_{tr}\), we can decompose the on a test point \(x \in \mathcal{D}_{te}\) as:
\[[\mathbb{E}\[\hat y(x) - y(x)]^2 = (\mathbb{E} \hat y(x) - \mathbb{E} y(x))^2 + \mathbb{V}[\hat y(x)] + \mathbb{V}[y(x)]]\]where \(y(x)\) is the ground truth. The first term is the squared bias, the second is the variance and the third is irreducible noise in the test data. The randomness in these variables is canonically taken to come from sampling noise, though as we’ll see shortly there are other sources too.
Looking at the terms more closely, bias is how much the average prediction – across models trained on different realisations of the training set – differs from the ground truth. Bias is typically interpreted as error resulting from incorrect assumptions about the data, a phenomenon otherwise known as underfitting. For example, trying to interpolate a polynomial function with a linear model leads to high bias.
The second term, variance, refers to how much each individual model’s prediction differs from the average prediction, and has historically been tied to overfitting to noise. If models’ predictions on the test set vary widely, it’s because they’ve all learned spurious correlations in their specific training set which do not hold on test data. The last term is irreducible noise in the test set.
Ideally, we’d like both bias and variance to be small. However, in practice, bias and variance seem to trade off against each other as model capacity is increased, resulting in the typical U-shaped curve for test risk in Figure 1a. This trade-off implies that to achieve the optimal test risk, a model should aim for the “sweet spot” where the trade-off is optimal. If models are larger than the optimal size, variance increases, and the result is overfitting to the training data and poor generalisation performance on test data. If they are smaller, they underfit the training data and do relatively poorly on all datasets.
This is the received wisdom from the bias-variance decomposition in the “classical” regime, and the dominating view pre-deep learning. This is mostly invalidated by deep neural networks, which generalise well despite being very large relative to the datasets they are trained on. The phenomenon of double descent (see e.g. Belkin et al., 2019) illustrates the capacity of large models to interpolate (i.e. perfectly fit) the data, and yet perform well to unseen data. In Figure 1b, as model size is increased, we move from the classical U-shaped risk curve to a peak at the interpolation threshold, with risk decreasing monotonically past the peak to values that are below the previous minimum.
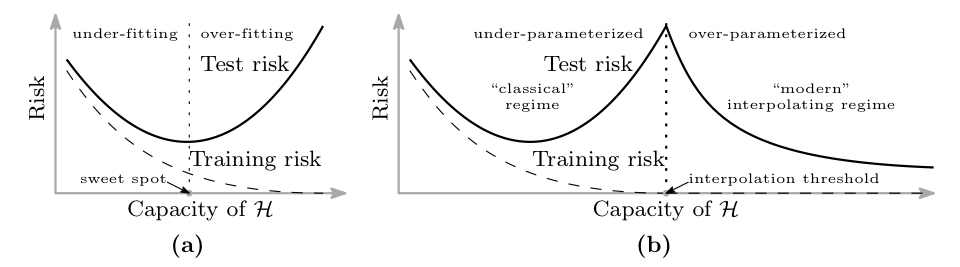
Figure 1. From Belkin et al., 2019. A visual representation of (a) the underparameterised regime, where the bias-variance trade-off occurs as models increase in capacity (here formalised as the size of a hypothesis class \(\mathcal{H}\)) and (b) the modern overparameterised regime, where test risk decreases despite models which are large relative to the size of their training datasets.
Double descent and variance
Several recent papers (Yang et al., 2020, Lin & Dobriban, 2021, Adlam & Pennington, 2020) examine double descent through the lens of the bias-variance decomposition. Broadly speaking, the main finding is that variance behaves unimodally – it increases, peaks, and then decreases monotonically. Depending on the magnitude of bias relative to variance, several test risk curves can be obtained, including double descent – see Figure 2. below.
The important observation here is that as models increase in size, variance decreases. To zoom out a bit, remember that variance captures the degree to which models differ in their predictions across different training runs. Decreasing variance means that models become more homogenous. In a sense, this follows directly from double descent, since we know that bias decreases with size and that after the interpolation threshold test risk decreases monotonically.
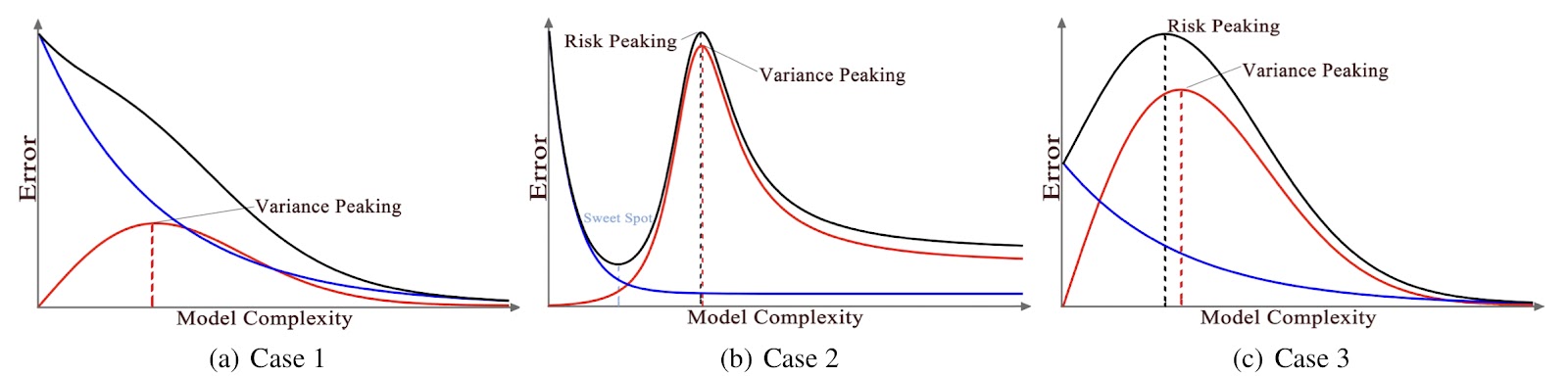
Figure 2. From Yang et al., 2020. A hypothetical test risk curve plotted against model complexity, alongside its bias and variance components. The three cases are as follows: (a) if bias dominates variance over the entire x-axis, then test risk follows a monotonic decrease; (b) if bias and variance dominate in different regimes, the test risk follows a double descent curve; (c) if variance dominates bias over the entire x-axis, then test risk is simply unimodal – without the initial decrease.
To try and understand what is happening with double descent, the latter two papers focus on decomposing variance into additional sources of randomness (training data sampling, parameter initialisation and label noise) and find that some components behave unimodally, while others increase up to the interpolation threshold and stay constant afterward (e.g. variance due to sampling and due to label noise, see Figure 3j).
There seems to not be any consensus on how to additionally decompose variance (including the order in which to condition on these sources of randomness – because conditioning isn’t symmetrical). Because of this, e.g. Rocks & Mehta, 2022 hint that some studies are led to incorrect conclusions about the relationship between variance and double descent.
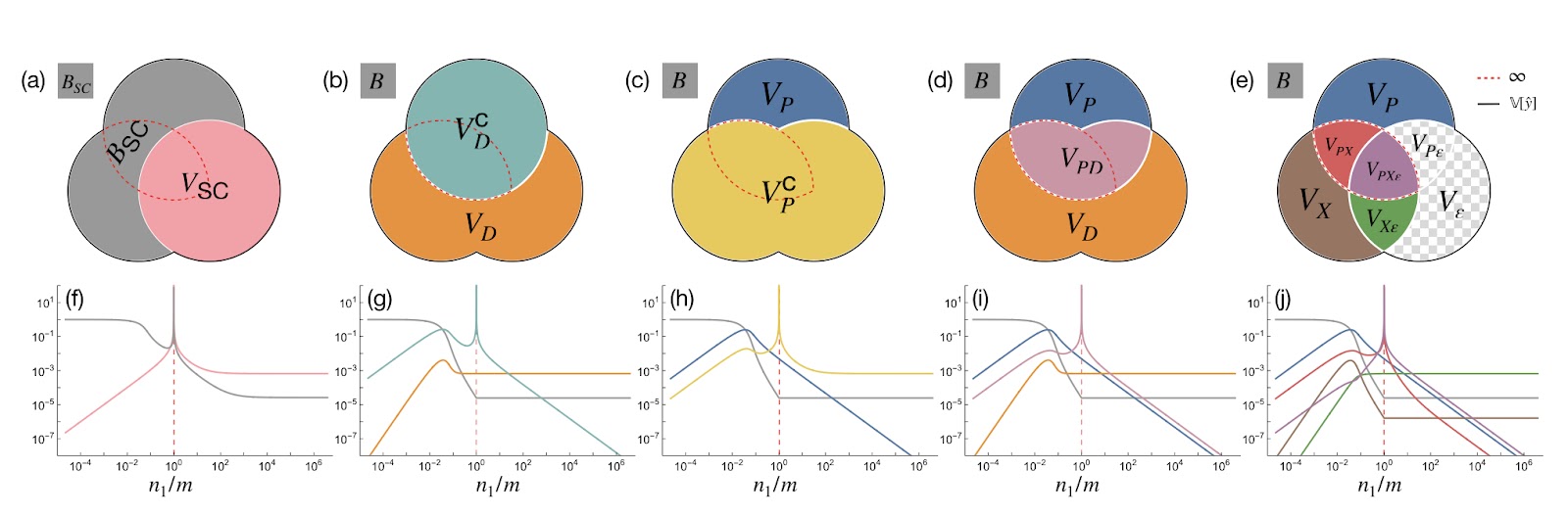
Figure 3. From Adlam & Pennington, 2020. Different decompositions of the bias (\(B\)) and the variance (\(V\)) of a neural network with hidden layer size \(n_1\) and dataset size \(m\). Most useful is the right-most decomposition into variance from sampling (\(V_X\)), variance from initialisation (\(V_P\)) and variance from label noise (\(V_\epsilon\)), along with their interaction effects, e.g. \(V_{PX}, V_{PX\epsilon}\). In figure (j) \(B, V_X\) and \(V_{X\epsilon}\) converge to a constant value after the interpolation threshold, and their values are no longer sensitive to increase in model size. All other sources of test risk are unimodal: they peak at the interpolation threshold and decrease with model size.
A few side-notes:
- Label noise exacerbates but doesn’t cause double descent, since other components of variance peak even in the absence of label noise (Fig. 3j).
- It turns out that in particular regimes the higher-level interaction effects between different sources of variance dominate the main effects, i.e. \(V_{si} > V_s > V_i\), where \(V_{s}\) is variance from sampling, \(V_i\) is variance from initialisation and \(V_{si}\) is the variance from the interaction between the two.
It’s also worth mentioning that these studies take place in the asymptotic setting, i.e. they investigate what happens if the number of samples in the training dataset and dimensionality of the data go to infinity while maintaining a fixed ratio. Lin & Dobriban, 2021 find that this ratio controls the unimodal behaviour of the variance: if the ratio is below a threshold, variance peaks, then decreases; otherwise it increases.
If this analysis is correct, as long as we control the ratio we can ensure that models become more homogenous as they become larger. It’s worth noting that this hasn’t been replicated yet, to my knowledge, and that this unimodal variance explanation for double descent is not the only hypothesis, see e.g. Kuzborskij et al., 2021 for an account of DD related to the smallest positive eigenvalue of the feature covariance matrix.
How might this turn out to be false?
First, it’s possible that the findings from analysis of variance are not robust to changes in architecture or learning task, though at least Yang et al. 2020 seem to cover quite a few experimental set-ups (including changing architecture and dataset as well as other potentially-less-impactful training hyperparameters). This means that it might be useful to do more experiments to probe the robustness of these findings. If they turn out to scale well/hold across architectures, then this is stronger evidence in favour of homogeneity.
Second, it could be that residual variance – variance that is not eliminated through training – is enough to invalidate the homogeneity hypothesis, in the sense that residual variance could lead to different behaviour/properties of models that exist at the same time. I’m not sure how likely this is, given that the residual variances seem to be quite small – on the order of 10^{-3} according to Adlam & Pennington, 2020 – though of course here the threshold is unknown. (How much variance implies heterogeneity doesn’t seem to be a well-posed question.)
I don’t have a good idea for how to resolve this uncertainty. It seems to me that unless we can find a more precise definition of homogeneity, we can’t say exactly how much residual variance matters.
Things I don’t yet understand
- How does the fixed-design/random-design decomposition affect the result? For example see Hastie et al., 2022.
- Lots of these experiments use random features, and it’s unclear to me why this is more appropriate/easy to analyse than shallow neural networks, which presumably are closer to what we care about.
- Where does the variance from optimisation fit in? Is it the same as variance from initialisation, which is where the optimiser starts? E.g. Neal et al., 2018 mention variance due to optimisation, but they don’t study how bias and variance change during training.
- They point to variance from optimisation as encompassing: random initialisation and stochastic mini-batching, but they also say that their results hold even with batch gradient descent.
Open questions
- Should we expect “prediction” homogeneity to translate to alignment properties?
- Why does variance have unimodal behaviour? It might be worth replicating the experiments in Lin & Dobriban, 2021 where they use the parameterisation level and data aspect ratio to control the variance.
- Yang et al., 2020 conjecture that it’s regularisation that leads to variance decreasing past the peak, though this seems like a broad remark that does not add much useful information.
Argument from simplicity bias
We have good empirical evidence that neural networks are biased toward simple functions which fit the data. There’s no consensus on the mechanism behind this bias, but there are lots of competing explanations.
One recent such explanation is that their parameter-function maps are biased toward low-complexity functions; that is, even before training NN architectures induce a strong preference for simplicity. See this LW article for a jumping-off point, or go directly to the technical papers: Valle-Perez, Camargo & Louis, 2018, Mingard et al., 2019, Mingard et al., 2021.
| If this analysis is correct, then various proposed mechanisms for why DNNs generalise which are related to optimiser choice or hyperparameter tuning are only small (or “second-order”) deviations from the posterior \(P_B(f | S)\) whose bias is essentially induced by the prior \(P(f)\). |
This might lead you to believe that given a fixed architecture, different initialisation schemes, optimisers, hyperparameters etc. do not contribute substantially to the properties that the trained system has, or, differently put, that different experimental setups do not result in systems which differ in the ways we care about.
This is consistent with the finding that variance decreases with scale, at least if we interpret the findings in Section 5 of Mingard et al., 2019 to mean that adding more layers results in stronger bias toward simple functions. I’d be excited about work that directly connects these two insights, especially since we don’t necessarily know yet why variance is unimodal.
I’m a bit more sceptical that this line of argument supports homogeneity directly, mostly because I don’t think that a biased parameter-function map explains all the properties of models found through e.g. SGD (nor do I think the Mingard et al. papers make these claims). If the influence of specific training hyperparameters is enough to induce heterogeneity between runs – again, only gesturing at the concept of heterogeneity rather than defining it – then even if the parameter-function map hypothesis of generalisation is true, it’s evidence against homogeneity.
How might this turn out to be false?
- The biased prior drives most of the inductive bias, but it doesn’t explain everything. Even if details about the training setup do not account for most of DNNs’ capacity to generalise, they may still account for some particular property which is relevant from an alignment perspective;
- Simplicity is not the same as homogeneity. Even if all functions that NNs tend to find are simple by some measure, it doesn’t mean that they are the same function. There might be some key input where two up-to-then identical functions diverge, which could lead to negative outcomes. Again, it’s possible that we won’t be able to prove that two such functions are the same.
- Objections to the biased prior hypothesis. It could be that the biased parameter-function map account of NN generalisation does not scale to larger networks/more complex architectures/other tasks (for some discussion, see this article). This might mean that some other hypothesis better explains NNs’ performance in the overparameterised regime – there are many related to: the stochasticity of gradient descent, the loss landscape (through basins of attraction or through flat minima), NNs’ similarity to GPs, implicit regularisation and others – which might lead us to update away from model homogeneity.
Summary
This article outlines two arguments from recent ML research for why homogenous take-off is a plausible story. One stems from an empirically observed decrease in variance with model size, which is consistent with the double descent phenomenon. The other is a consequence of the finding that neural networks are a priori biased toward simple functions, which means that they are likely to find solutions with similar properties regardless of the particular training parameters.
I think there’s still work to be done on both of these arguments, and I’d be much more willing to update in favour of homogenous takeoff if the findings were more robust or we had a better understanding of e.g. why variance is unimodal. But it seems worthwhile to make this connection and get more people thinking and talking about the likelihood of homogeneity in take-off scenarios.